



Introduction
Recently for an open data integration project I had to select some tools in order to be able to process geospatial data. I had a couple of choices: I could use R and try to work out a solution with the packages available on the server or use Talend. One of the biggest restrictions was, the development environment had no internet connection due to security policies and I wanted to try some options iteractively. I decided to give Talend a try and asked the system admins to install the spatial plugin. I only had tried Talend before to accomplish some exercises from the book Talend for Big Data but never used it for a “real-world” project, which was challenging but also made me feel motivated.
Software requirements
Talend open studio for big data
https://www.talend.com/download/
Spatial extension for Talend
https://talend-spatial.github.io/
The experiment
Input data
Customers coordinates: a flat file containing x,y coordinates for every customer.
Municipalities in Austria: a shape file with multi-polygons defining the municipalities areas in Austria: source
Goal
Use the x,y coordinates from the customers to “look-up” the municipality code GKZ in the shape file, which in german stand for “Gemeindekennzahl”. The idea is to determine in which municipality lies every point (customer location).
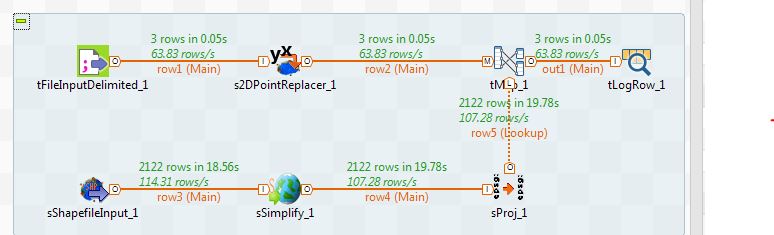
This is an overview of the overall Talend job
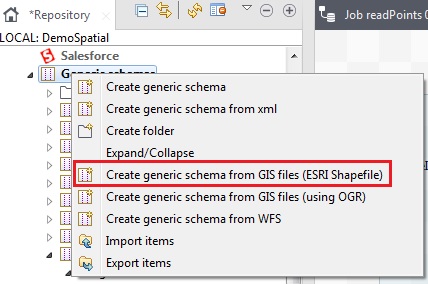
Create a generic schema
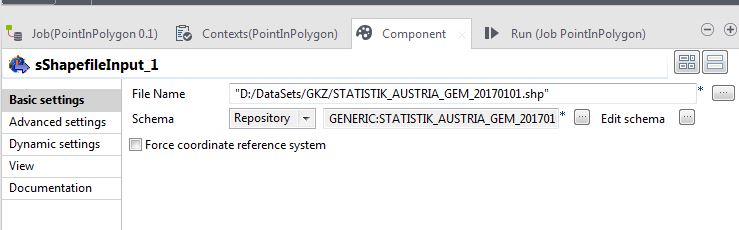
Use a sShapeFileInput component
The shapefile contains multipolygons and I want to have polygons. My solution was to use an sSimplify component. I used the default settings. You may need to analyze or find in the source metadata what kind of data is available within the shape file.
The projection of the shapefile was “MGI / Austria Lambert” which corresponds to EPSG 31287. I want to re-project it as EPSG 4326 (GCS_WGS_1984) which is the one used by my input coordinates.

I read the x, y coordinates from a csv file.
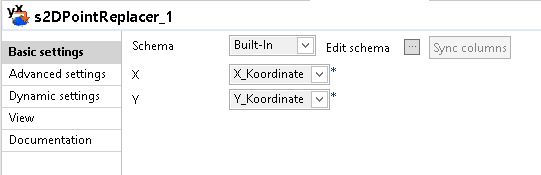
With a s2DPointReplacer I converted the x,y coordinates as Point(x,y) (WKT: well-known text)
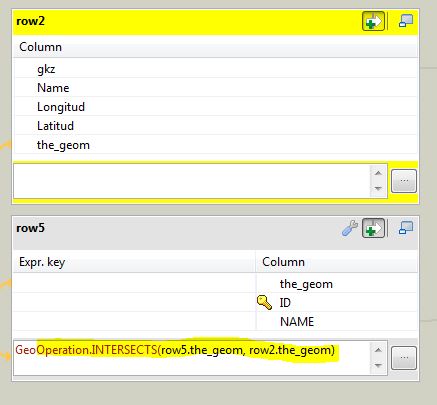
Finally I created an expression in a tMap just to get the polygon and point intersection. The “contains” function would also work:
Conclusion
Talend did the job and I recommend it as an alternative not only for classical ETL projects but also to create analytical data sets to be consumed by data scientists. Sometimes data cleansing (or data munging/wrangling, or whatever you want to call it) could be cumbersome with scripting languages. With Talend the jobs are easy to understand, could be fully parameterized and reused.

Leave a comment