



Disclaimer: I am not a Windows or Microsoft fan, but I am a frequent Windows user and it’s the most common OS I found in the Enterprise everywhere. Therefore, I decided to try Apache Zeppelin on my Windows 10 laptop and share my experience with you. The behavior should be similar in other operating systems.
Introduction
It is not a secret that Apache Spark became a reference as a powerful cluster computing framework, especially useful for machine learning applications and big data processing. Applications could be written in several languages as Java, Scala, Python or R. Apache Zeppelin is a Web-based tool that tries to cover according to the official project Website all of our needs (Apache Zeppelin):
- Data ingestion
- Data discovery
- Data analytics
- Data visualization and collaboration
The interpreter concept is what makes Zeppelin powerful, because you can theoretically plug in any language/data-processing-backend. It provides built-in Spark integration, and that is what I have tested first.
Apache Zeppelin Download
You can download the latest release from this link: download
I downloaded the version 0.6.2 binary package with all interpreters.
Since this version, the Spark interpreter is compatible with Spark 2.0 and Scala 2.11
According to the documentation, it supports Oracle JDK 1.7 (I guess it should work with 1.8) and Mac OSX, Ubuntu 14.4, CentOS 6.X and Windows 7 pro SP1 (And according to my tests also with Windows 10 Home).
Too much bla bla bla, let’s get started.
Zeppelin Installation
After download open the file (I used 7 Zip) and extract it to a proper location (in my case just the c drive to avoid possible problems)
Set the JAVA_HOME system variable to your JDK bin folder.
Set the variable HADOOP_HOME to your Hadoop folder location. If you don’t have the HADOOP binaries you can download my binaries from here: Hadoop-2.7.1
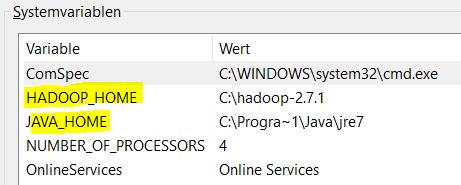
I am not really sure why Hadoop is needed if Zeppelin supposed to be autonomous but I guess Spark looks for the winutils.exe if you are using Windows. I posted about it in my previous post: Apache Spark Installation on Windows 10
This is the error I found in the Zeppelin logs (ZEPPELIN_DIR\logs –> there is a file for the server log and a separated file for each interpreter):

Zeppelin Configuration
There are several settings you can adjust. Basically, there are two main files in the ZEPPELIN_DIR\conf :
- zeppelin-env
- zeppelin-site.xml
In the first one you can configure some interpreter settings. In the second more aspects related to the Website, like for instance, the Zeppelin server port (I am using the 8080 but most probably yours is already used by another application)
If you don’t touch the zeppelin-env file, Zeppelin use the built-in Spark version, which it has been used for the results posted in this entry.
Start Zeppelin
Open a command prompt and start Zeppelin executing the zeppelin.cmd in Drive:\ZEPELLIN_DIR\bin\zeppelin.cmd
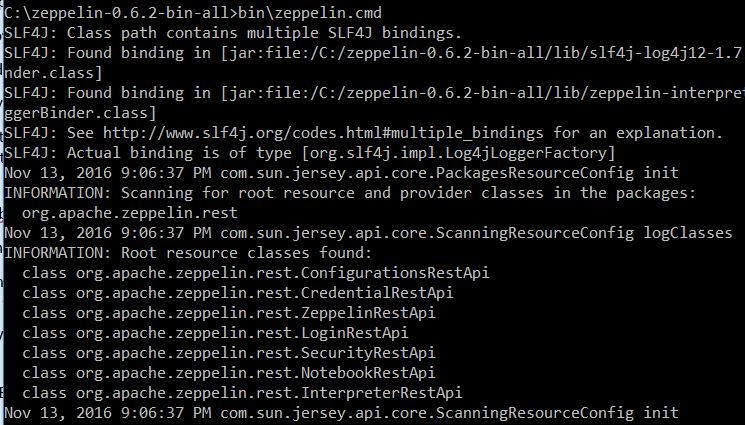
Then, open your favorite browser and navigate to localhost:8080 (or the one you set in the zeppelin-site.xml)
You should see the starting page. Verify that the indicator in the top-right-side of the windows is green, otherwise your server is down or is not running properly)
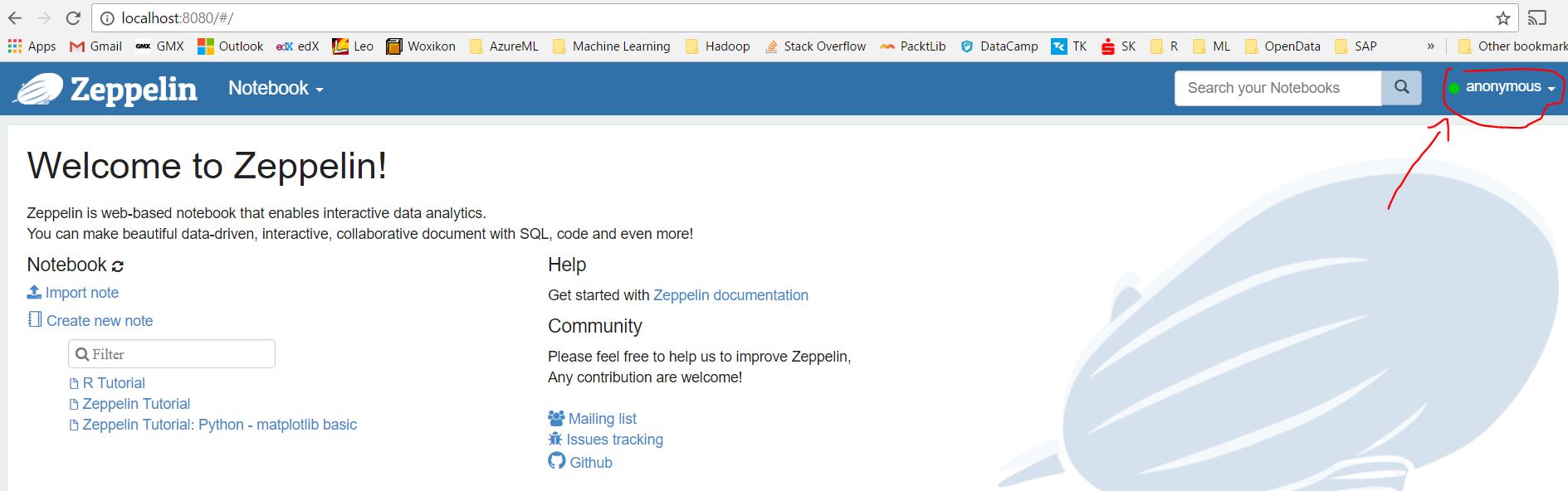
If you have not configured Hive, before start trying the tutorials included in the release, you should need to set the value of the zeppelin.spark.useHiveContext to false. Apart from the config files, Zeppelin has an interpreter configuration page. You can find it by clicking on your user “anonymous” –> Interpreter
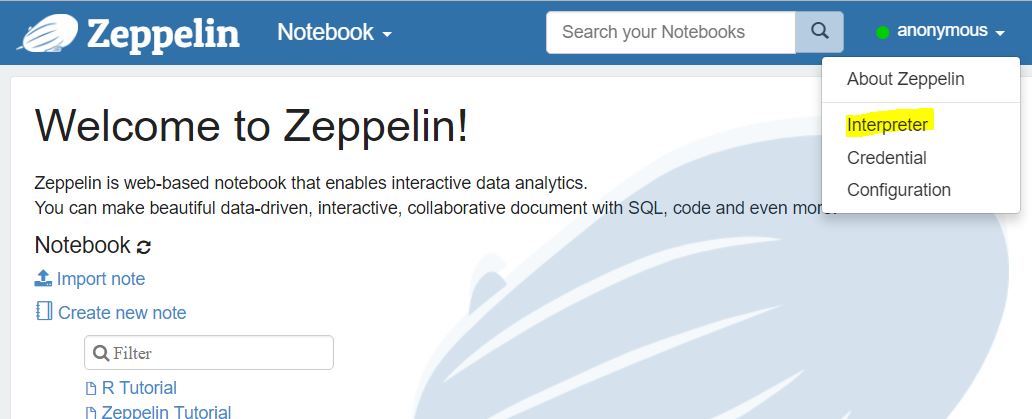
Scroll-down to the bottom where you’ll find the Spark config values:
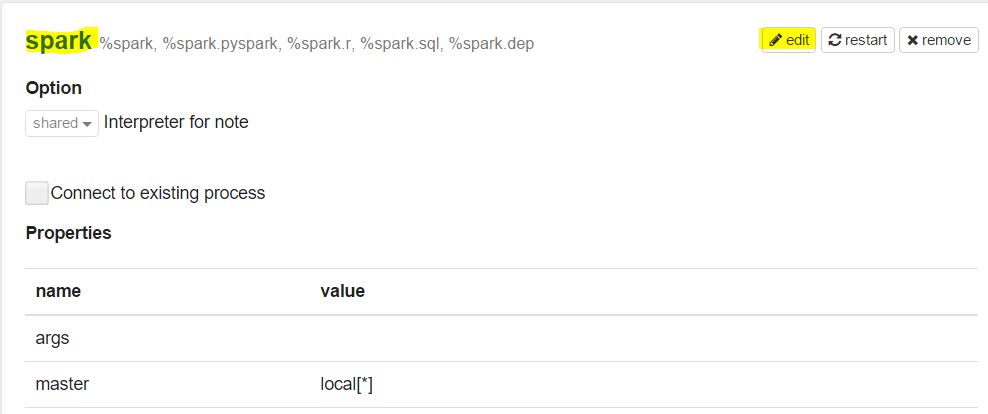
Press on the edit button and change the value to false in order to use the SQL context instead of Hive.
Press the Save button to persist the change:

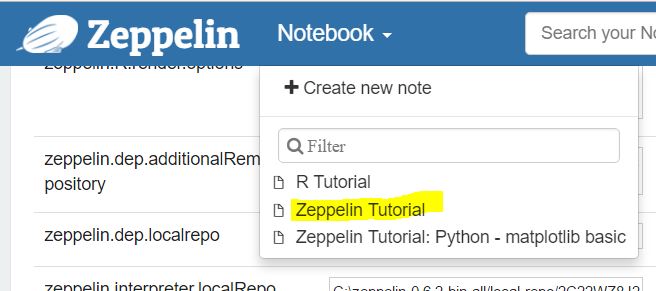
Now let’s try the Zeppelin Tutorial
From the Notebook menu click on the Zeppelin Tutorial link:
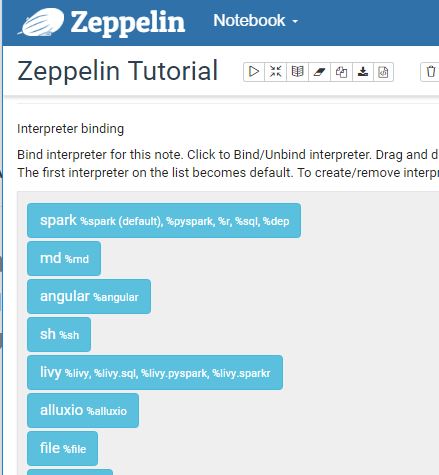
The first time you open it, Zeppelin ask you to set the Interpreter bindings:
Just scroll-down and save them:
Some notes are presented with different layouts. For more about the display system visit the documentation online.
Other possible annoying error
I was getting the following error when tried to run some notes in the Zeppelin Tutorial:
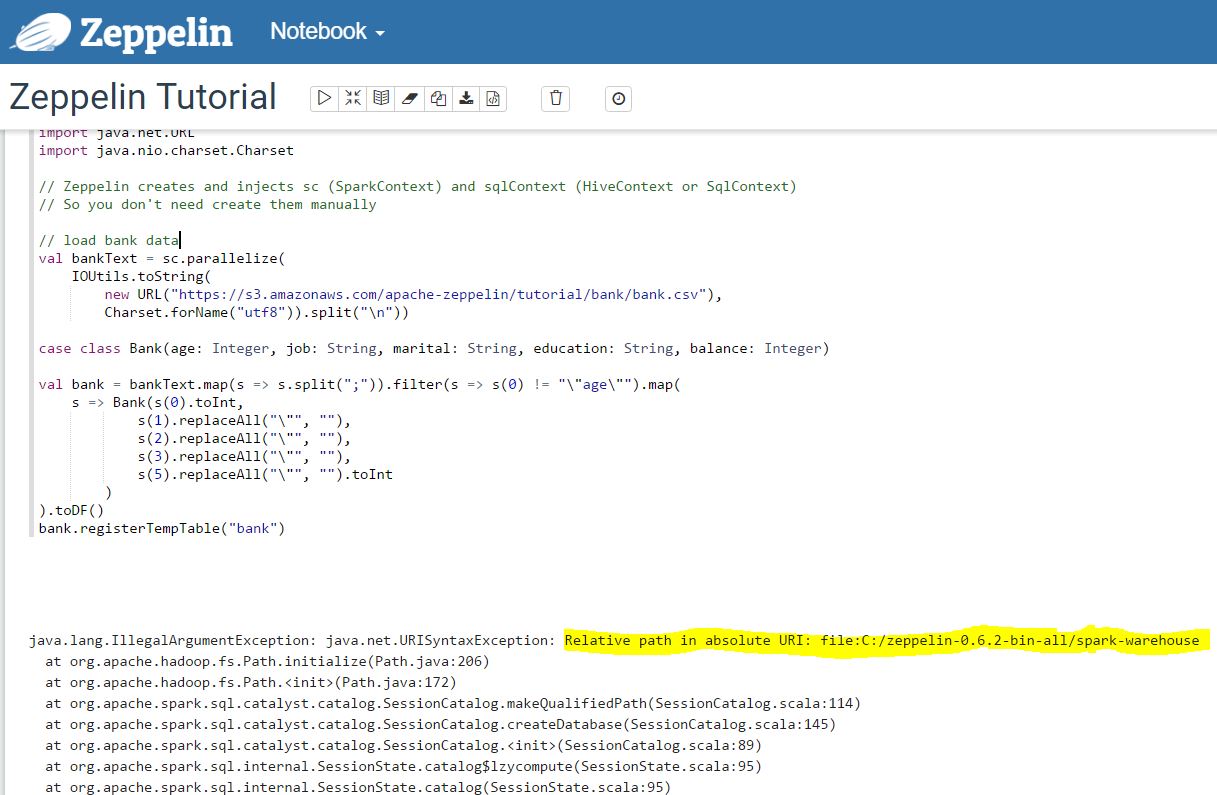
I found a suggested solution in the following stack overflow question: link
An URI syntax exception trying to find the folder spark-warehouse in the Zeppelin folder. I struggled a little bit with that. The folder was not created in my Zeppelin directory, I thought it was a permissions problem, so I created it manually and assigned 777 permissions.
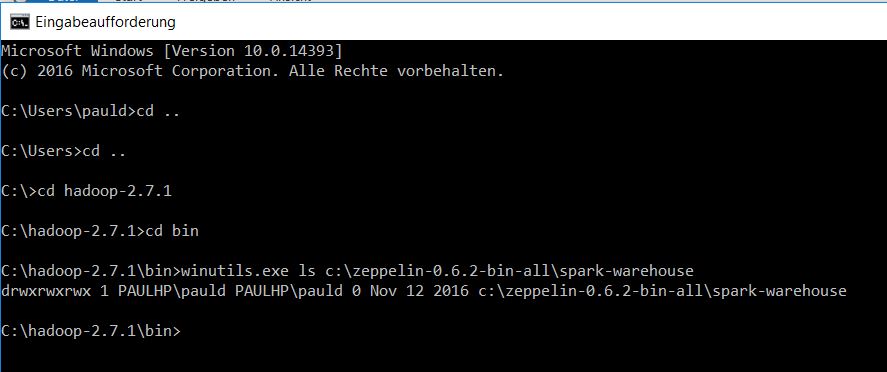
It still failed. In the link above a forum user suggested to use triple slashes to define the proper path file:///C:/zeppelin-0.6.2-bin-all/spark-warehouse
But I still don’t know where to place this configuration. I couldn´t do it in the spark shell, also not while creating a spark session (zeppelin does it for me) and the conf/spark-defaults.conf doesn´t seem to be a good idea for Zeppelin because I was using the spark built-in version.
Finally, I remembered that is possible to add additional spark setting in the interpreter configuration page and I just navigated there and created it:
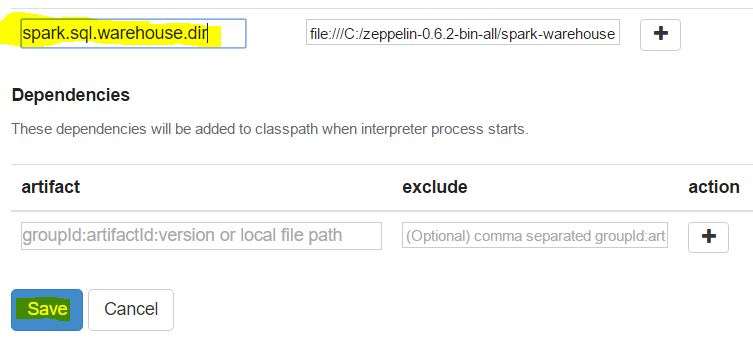
Just as additional info, you can verify the settings saved in this page in the file Drive:\ZEPELLIN_DIR\conf\interpreter.json
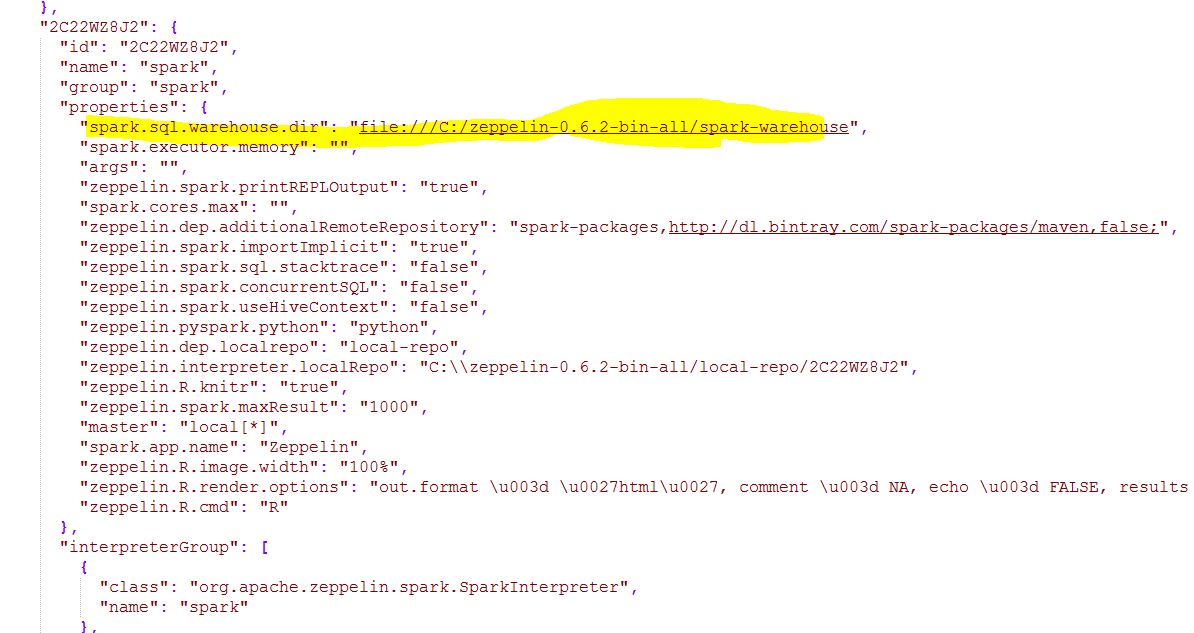
After these steps, I was able to run all of the notes from the Zeppelin tutorials.
Note that the layout from the tutorial is telling you more or less the order in which you have to execute the notes. The note “Load data into table” must be executed before you play the notes below. I guess that is the reason it spans over the whole width of the page, because it must be executed before you visualize or analyze the data, while the notes below could be executed in parallel, or in any order. I mean, this layout is not a must but it helps to keep an execution order.
I hope this helps you on your way to learn Zeppelin!

Leave a comment