



- Introduction
- Use Case – Logical environment in data lake
- Use Case – Switching source folder in a dataset
- The Solution
- Example
- Conclusion
Introduction
Parametrization was always a key aspect in ETL development to be able to move scripts, packages, jobs or whatever artifact you use into another environment. With modern data processing tools this situation has not changed.
One of the first things I missed when I changed from tools like SSIS or Talend to Azure Synapse or Data Factory was a configuration database, file or similar mechanism (I may be getting old).
Particularly in Synapse, there are even no global parameters like in Azure Data Factory.
When you want to move your development to another environment, typically CI/CDs pipelines are used. These pipelines consume an ARM template together with its parameter file to create a workspace in a target environment. The parameters can be overriding in the CD pipeline as explain here: https://techcommunity.microsoft.com/t5/data-architecture-blog/ci-cd-in-azure-synapse-analytics-part-4-the-release-pipeline/ba-p/2034434
Even so, I have not found a proper way to change the values of a pipeline parameter (the same for data flows and datasets parameters). I saw some custom parameters manipulation to set the default value of a parameter and then deploy it without any value, or even JSON manipulation with PowerShell (the dark side for me).
Use Case – Logical environment in data lake
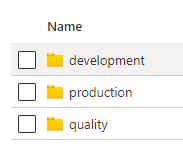
Suppose you have separated environments, with let’s say, a different subscription or just a different resource group per environment, you already set the template parameters and the linked servers are properly configured. Now suppose, and I have experienced this case in real projects, you have a common data lake for all environments with a logical separation using a folder layout:

If you have a dataset pointing to any folder of the storage account above, you need to parameterize it to be transportable to another environment. Let’s figure out how to implement this feature and deploy the workspace to quality or production.
Use Case – Switching source folder in a dataset
Imagine you have different source directories in the same data lake, even if you have one different data lake per environment. You sample some data, maybe with a notebook, to be able to develop with a small representative dataset. You would like to execute the pipeline and use a parameter to switch between different source directories.
Remark: if this layout makes sense or not is another discussion.
The Solution
One way to overcome this issue is by creating a parameters table in a database. The pipelines will read this configuration at runtime and provide the configured parameters where it is needed:
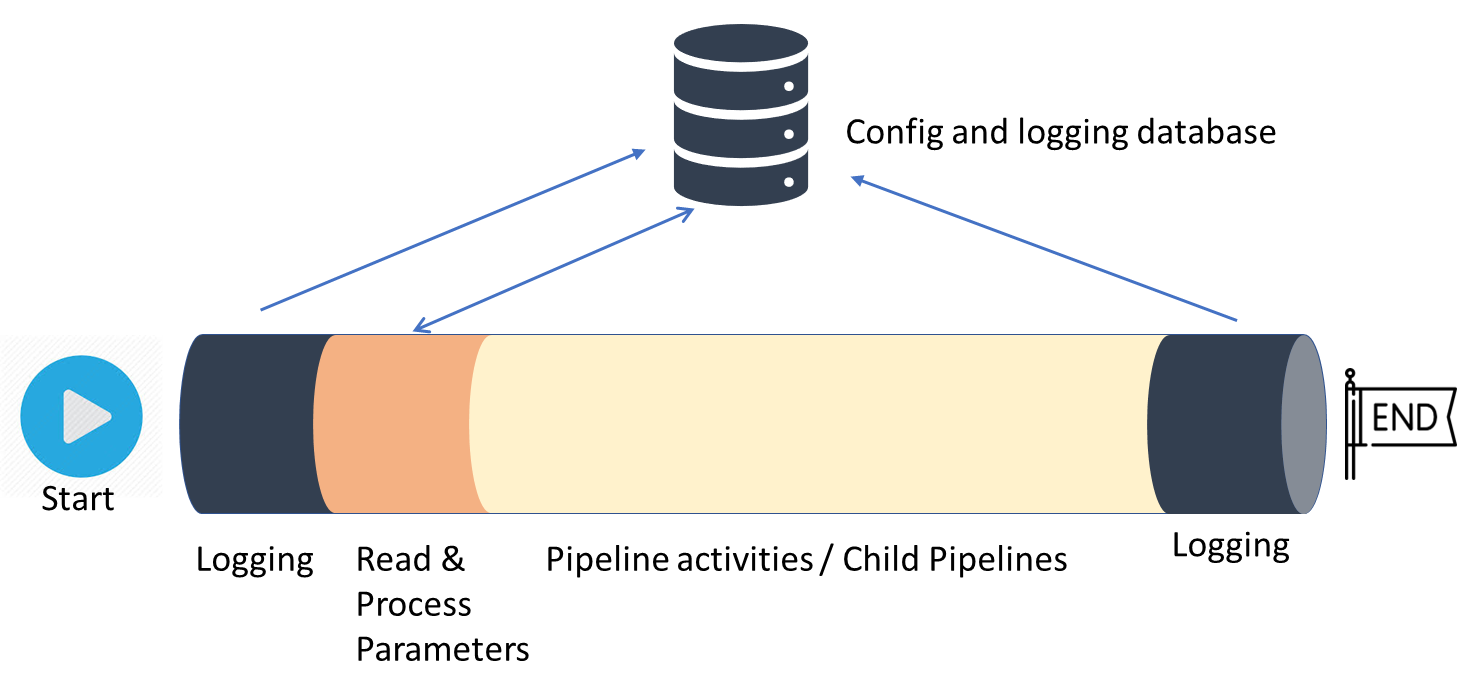
The pipeline may have a custom logging step or even a pre-processing pipeline, then the parameters are read from the parameters table in a configuration database, the core of the pipeline consumes the retrieved parameters and finally you may want to have some general post-processing logic at the end.
Example
If you want to reproduce this example you will need at least:
- A Synapse workspace
- A dedicated SQL pool (or another database)
- An azure data lake gen 2
- A sample csv file
Overview
Let’s do a quick example and load a csv file located in a data lake to a table in a SQL dedicated pool.

The pipeline is simplified to highlight only how to use the alternative parametrization approach.
Database objects
This is the DDL to recreate the database code. It is adapted to run in a SQL dedicated pool but you may want to hold this configurations in another database:
/* ---------------------------------------------------------
---- CREATE schema config
---------------------------------------------------------- */
IF(NOT EXISTS (select * from INFORMATION_SCHEMA.SCHEMATA where SCHEMA_NAME = 'config'))
BEGIN
EXEC('CREATE SCHEMA config AUTHORIZATION [dbo]')
END;
/* ---------------------------------------------------------
---- CREATE TABLE config.Pipeline_Parameters ------------
---------------------------------------------------------- */
-- Drop the table if exists
IF(EXISTS (select * from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA = 'config' and TABLE_NAME = 'Pipeline_Parameters'))
BEGIN
DROP TABLE config.Pipeline_Parameters;
END;
-- Create a heap table to quickly insert data from S1
CREATE TABLE [config].[Pipeline_Parameters](
[Synapse_Object_Name] [nvarchar](120) NOT NULL,
[Synapse_Object_Type] [nvarchar](50) NOT NULL,
[Parameter_Name] [nvarchar](50) NOT NULL,
[Parameter_Value] [nvarchar](50) NULL
)
WITH
(
DISTRIBUTION = REPLICATE,
CLUSTERED INDEX ([Synapse_Object_Name])
);
INSERT INTO [config].[Pipeline_Parameters]
VALUES('Pipeline_Demo', 'Pipeline', 'source_folder', 'sample');
GO
INSERT INTO [config].[Pipeline_Parameters]
VALUES('Pipeline_Demo', 'Pipeline', 'env', 'development');
GOThe result is a table like this:

Remark: The “Synapse_Object_Name” must have the same pipeline name. I created a column “Synapse_Object_Type” to generalize, in case you want to parameterize other objects.
Now that we prepared the parameters let’s turn back to the pipeline.
Input data
The sample file is stored in a data lake (ADLSv2) with this layout (this is just a sample layout design, not a recommendation):
Top level to logically split environments:
A level to split sample and source system data:
A specific source system folder:

Finally, the csv file:
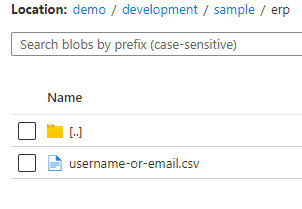
To bring this data into synapse let’s create a new integration dataset. This dataset will be able to switch between different folders:
- Create a new integration dataset from ADLSv2 of type DelimitedText and go to the parameters tab
- Create parameter called source_folder
- Add the default value: development/sample/erp

- Return to the “Connection” tab and add the following configuration:

Note how the dataset parameter is consumed in the “File path” value.
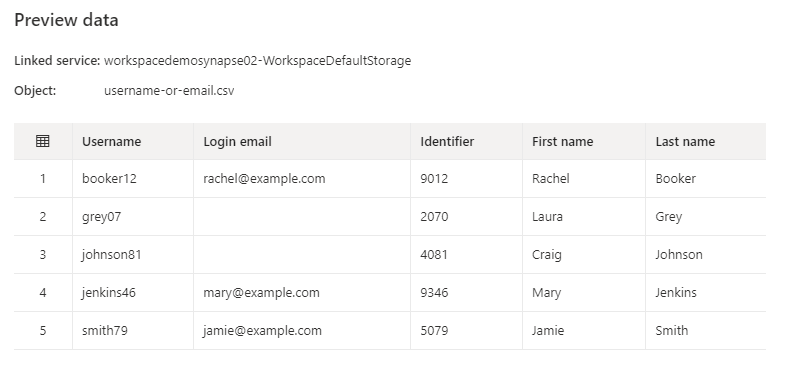
If you set all properly you should be able to preview the data. In my case:
Read parameters from the database table
Let’s continue with another integration dataset, this time of type “Azure Synapse Analytics” (you will have to adjust it to the database you are using):
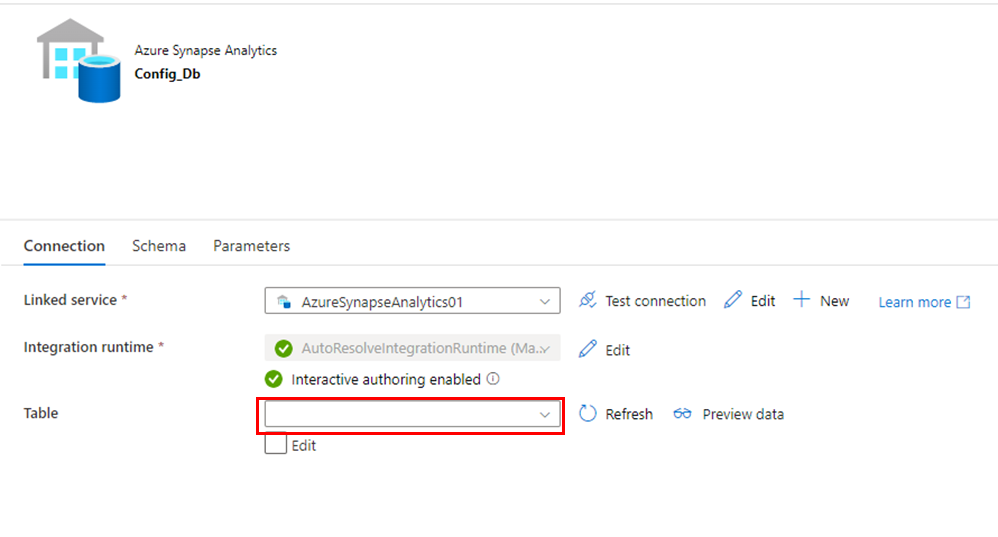
I don’t select any table since we are going to use this dataset to send all queries we want to execute against the config database.
This is the query to read the parameters:
select N'{' + STRING_AGG(params,',') + '}' as params
from
(
select '"' + + Parameter_Name + '":"' + Parameter_Value + '"' as params
from [config].[Pipeline_Parameters]
where Synapse_Object_Name = '@{pipeline().Pipeline}'
and Synapse_Object_Type = 'Pipeline'
) as Qry
Please note the pipeline name is used to filter the relevant parameters. These are transformed into a JSON string to ease their consumption by the pipeline:
{"env":"development","source_folder":"sample"}
I used two “Set Variable” activities to extract the parameters in single variables:
Pipeline variables
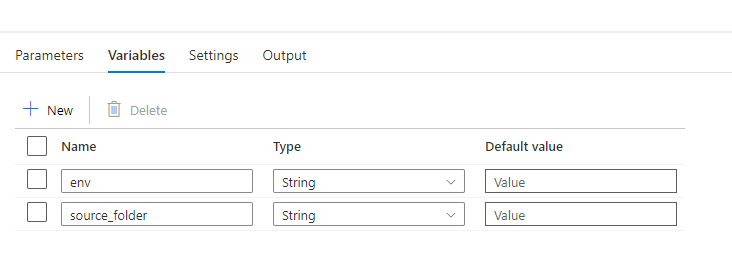
env parameter:

Value:
@{json(activity('Get_Parameters').output.firstRow.params).env}source_system parameter:

Value:
@{json(activity('Get_Parameters').output.firstRow.params).source_folder}Target Table
To copy the data into a target table add a “Copy” activity to the canvas and configure it as follows:
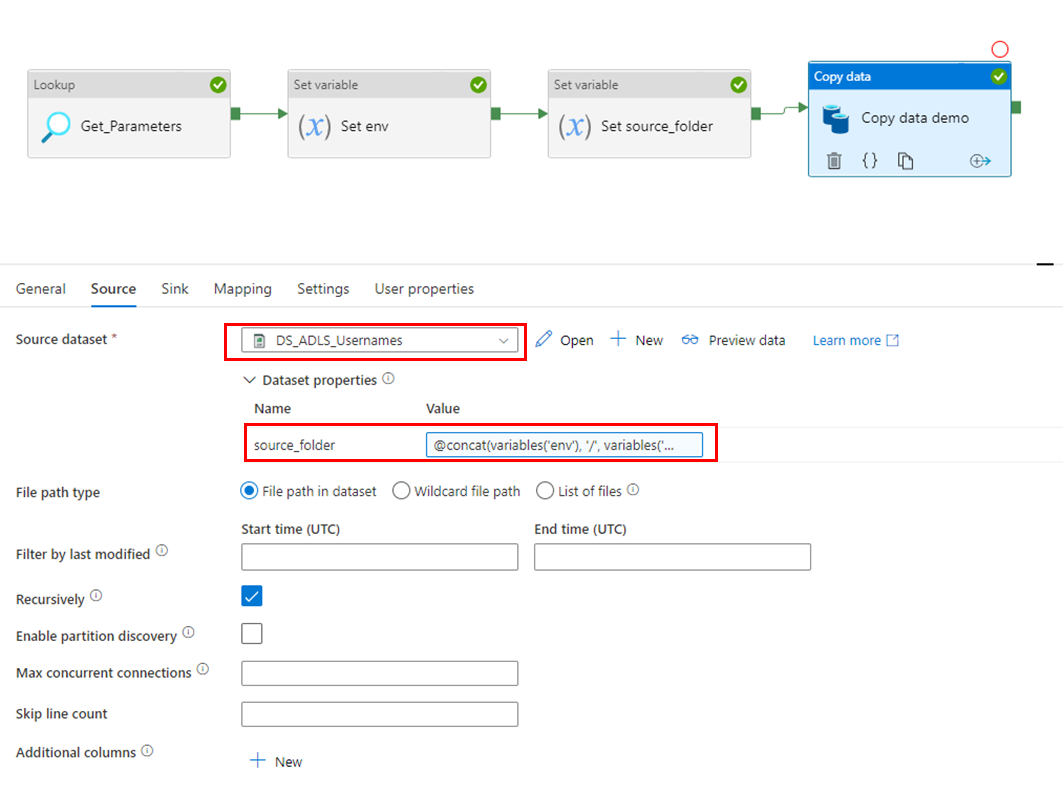
- Select the dataset we have created for the csv file as “Source”
- Since this dataset has a parameter, a value can be provided. Here is where we pass our parameters from the database:
@concat(variables('env'), '/', variables('source_folder'), '/erp')If everything went well the rows were copied to the target table:
Conclusion
In this article an alternative parametrization for Synapse pipelines was presented together with an example. This method is also applicable for Azure Data Factory. This is not a standard approach and you should consider whether it fits your current technical requirements or not.
I also implemented a more complex parameters table design, in which you create another level I called parameter group. In this way you can retrieve different sets of parameters depending on the pipeline logic, for example, if you have multiple source or target datasets and your pipeline iterates over them.

Leave a comment